Reuse-Centric Programming System Support of Machine Learning
09/2016 - present
(Figure: Reuse-centric optimization.)
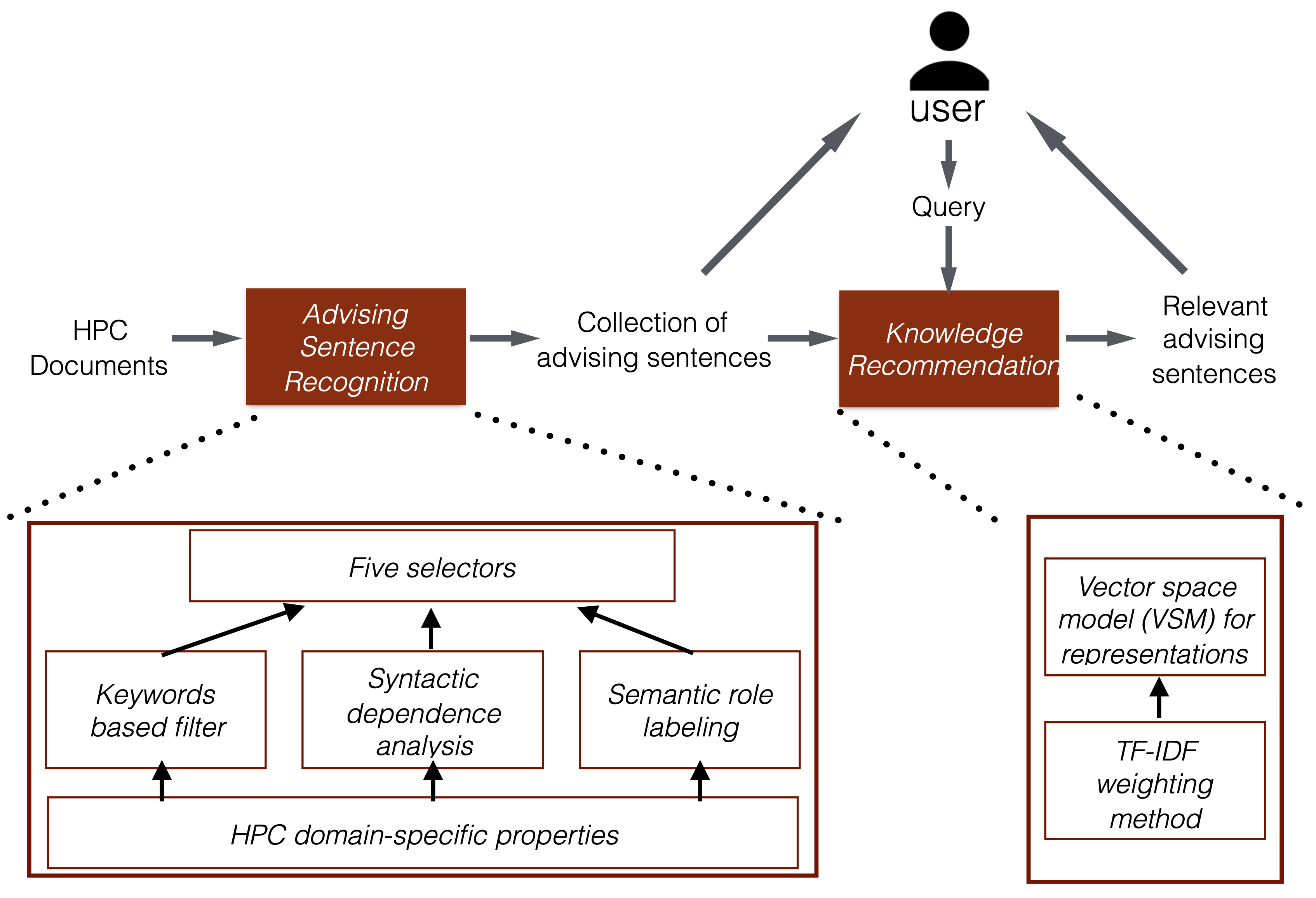
As a critical link between software and computing hardware, programming system plays an essential role in ensuring the efficiency, scalability, security, and reliability of machine learning. This project examines the challenges in machine learning from the programming system perspective by developing simple yet effective reuse-centric approaches. Specifically,
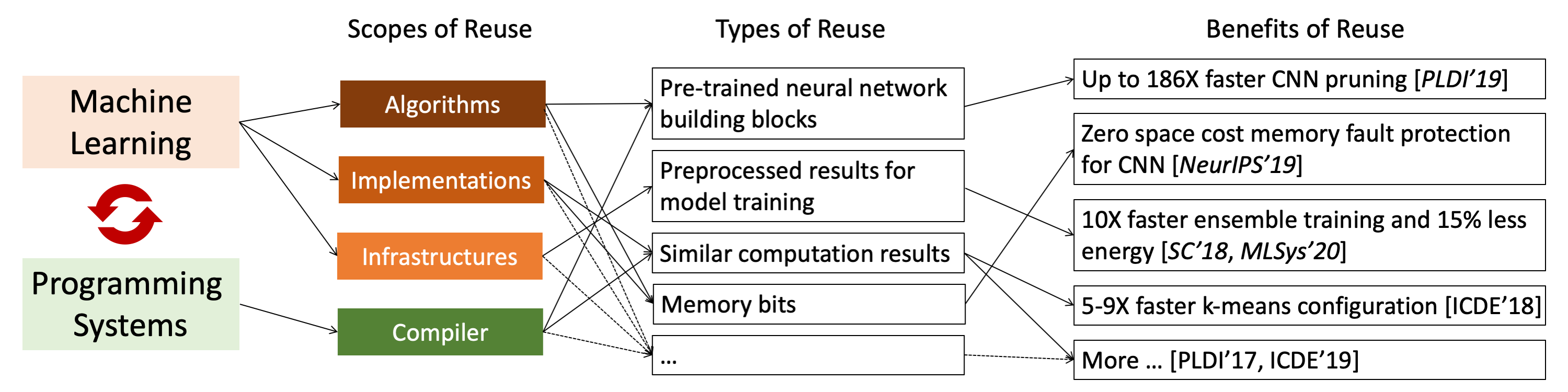
- Proposed a flexible ensemble DNN training framework for efficiently training a heterogeneous set of DNNs; achieved up to 1.97X speedups over the state-of-the-art framework that was designed for homogeneous DNN ensemble training. (Published in [MLSys'20])
- Proposed in-place zero-space ECC assisted with a new training scheme, weight distribution-oriented training, to provide the first known zero space cost memory protection for CNNs. (Published in [ NeurIPS’19])
- Developed a compiler-based framework that, for the first time, enables composability-based CNN pruning by generalizing Teacher-Student Network training for pre-training common convolutional layers; achieved up to 186X speedups. (Published in [ PLDI'19])
- Accelerated CNN training by identifying and adaptively avoiding similar vector dot products during training on the fly; saved up to 69% CNN training time with no accuracy loss. (Published in [ICDE'19])
- Improved the performance of DNN ensemble training by eliminating pipeline redundancies in preprocessing through data sharing; reduced CPU usage by 2-11X. (Published in [SC'18])
- Accelerated K-Means configuration by promoting multi-level computation reuse across the explorations of different configurations; achieved 5-9X speedups. (Published in [ICDE'18])
- Accelerated distance calculation-based machine learning algorithms (K-Means, KNN, etc.) by developing Triangle Inequality-based strength reduction; produced tens of times of speedups. (Published in [PLDI'17])